Map
Overview
There are 4 commonly used implementations of Map in Java SE - HashMap, TreeMap, Hashtable and LinkedHashMap. If we use only one sentence to describe each implementation, it would be the following:
- HashMap is implemented as a hash table, and there is no ordering on keys or values. It also allow null key or null value but hashtabl does not.
- TreeMap is implemented based on red-black tree structure, and it is ordered by the key.
- LinkedHashMap preserves the insertion order
- Hashtable is synchronized, in contrast to HashMap. It has an overhead for synchronization. This is the reason that Hashtable should be used if the program requires thread-safe.
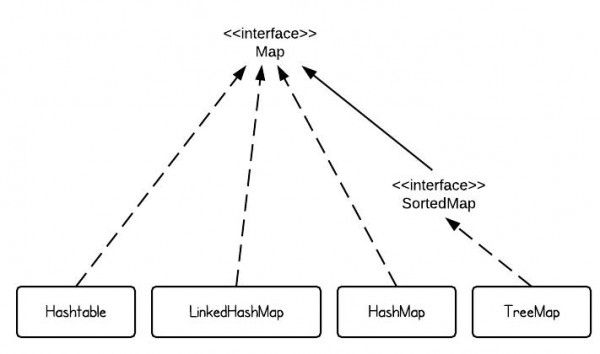
Note that the HashSet doesn't implement Map interface but it is based on HashMap. It contains HashMap insided as the value storage.
Hash Code and Equals Functions
The Java super class java.lang.Object has two very important methods defined:
public boolean equals(Object obj)
public int hashCode()
They have been proved to be extremely important to understand, especially when user-defined objects are added to Maps.
Once you override the equal() function, you must be careful to treat the hashCode() function. The contract between equals() and hashCode() is that:
- If two objects are equal, then they must have the same hash code.
- If two objects have the same hashcode, they may or may not be equal.
The default implementation of hashCode() in Object class returns distinct integers for different objects. So you have to decide hashCode() function according to your requirement. Sometimes, the same properties can be regarded as the same object, then hashCode() function should just build by the character on these properties.
Hash Collision
Closed hashing:
Linear Probing, Quadratic Probing, Double hashing(Constant prime as the next hash size( x - val%x));
Open hashing:
Chaining Address. key-value pairs are stored in linked lists attached to cells of a hash table.
How Java Map classes handle collision?
Hash tables applied the chaining address
Step 1: By having each bucket contain a linked list of elements that are hashed to that bucket. This is why a bad hash function can make look-ups in hash tables very slow. Because the bad hash function make the items location less disperse and lead to some clusters.
Step 2: What if the nodes in HashMap are almost fulled? Two concept need to be introdued firstly:
- Threshold
- Load Factor
Threshold is a value when the number of entry nodes in HashMap touch this value, the resize() function should be triggered. Threshold value should be evaluated by the loadFactor which is set 0.75 as its default value.That means .
Step 3: Resize and rehash. The hash function returns an integer and the hash table has to take the result of the hash function and mod it against the size of the table that way it can be sure it will get to bucket. so by increasing the size it will rehash and run the modulo calculations which if you are lucky might send the objects to different buckets.